
Two digital humanities researchers from the South African Centre for Digital Languages Resources (SADiLaR) attended the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022) in Abu Dhabi from 7-11 December 2022.
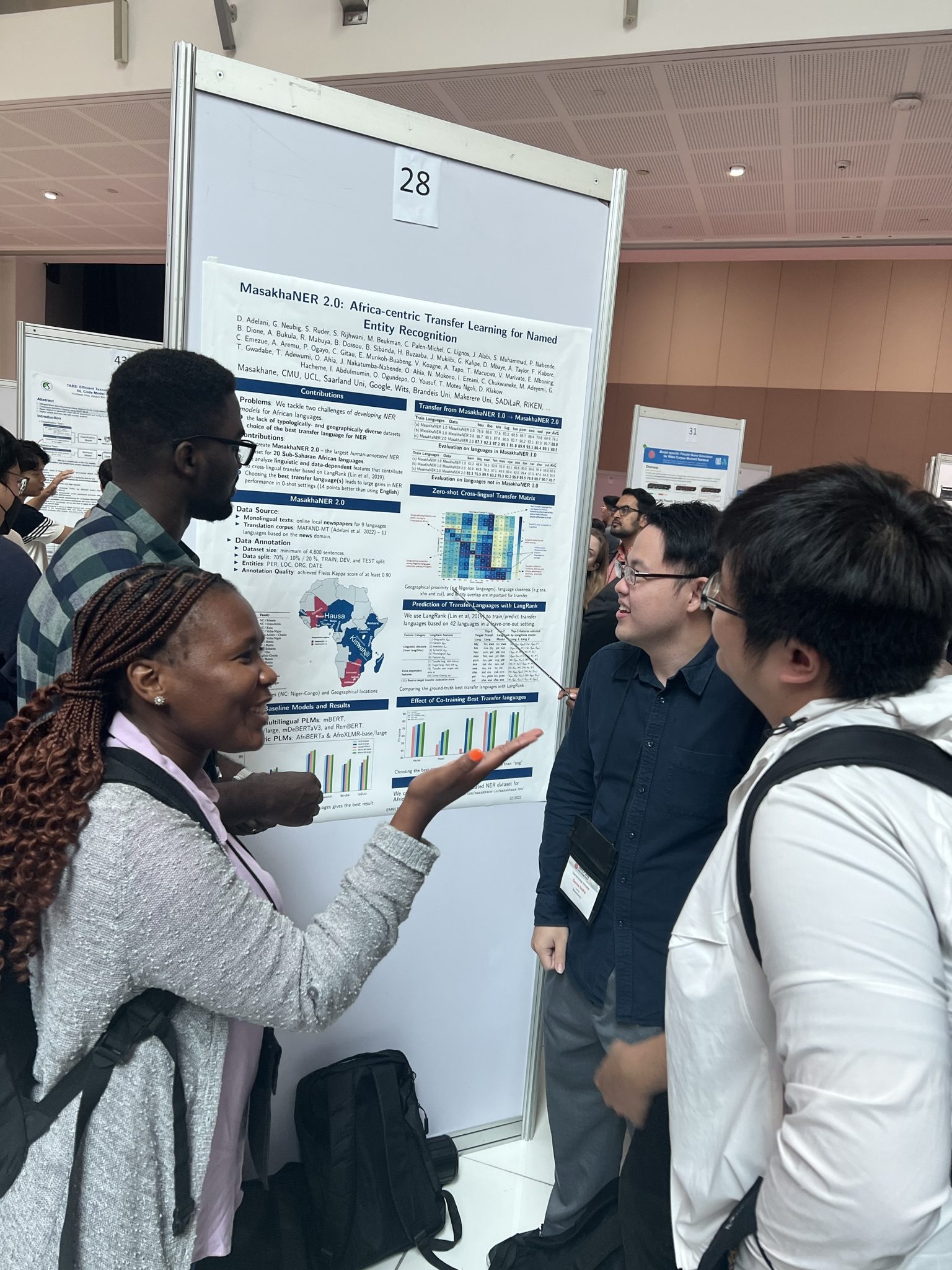
It was the first time that Andiswa Bukula and Rooweither Mabuya, SADiLaR language researchers for IsiXhosa and IsiZulu respectively, had the opportunity to attend a Natural Language Processing (NLP) conference. They attended many interesting sessions and presented a poster on MasakhaneNER 2.0: Africa-centric Transfer Learning for Named Entity Recognition, the largest human-annotated NER dataset for 20 African languages.
The conference was hosted at the Abu Dhabi National Exhibition Centre by New York University Abu Dhabi (NYUAD), in partnership with Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), and featured keynote speeches by leading voices in artificial intelligence, including Mona Diab, lead AI research scientist with Meta, and Professor of Computer Science at the George Washington University; Neil Cohn, an American cognitive scientist best known for his research on the overlap in structure and cognition between language and graphic communication including comics and emojis; Gary Marcus, a scientist, best-selling author, and serial entrepreneur; and Nazneen Rajan, research lead at Hugging Face, a startup with a mission to democratise machine learning. The conference also comprised 24 workshops and six tutorials. About 2500 participants attended the five-day conference both virtually and in person.
Shining on the global stage
“It was very intriguing to be part of such an experience,” says Andiswa Bukula. “Natural Language Processing (NLP) is a field we are slowly being introduced to as budding South African researchers.”
The immediate thing that stood out to Bukula was the beauty of Abu Dhabi and how beautiful their culture and cultural practices are. The conference itself gave her the opportunity to learn more about the research being done on a global scale pertaining NLP. “And, to be able to share what we are doing within the South African context on a global stage was the highlight of the entire conference for me, especially speaking about some of our indigenous languages in South Africa and the larger contribution we did in the creation of the largest human-annotated Named Entity Recognition (NER) dataset for African languages,” she comments.
According to Rooweither Mabuya it was a real privilege to attend one of the best events in the field. “As a result of attending the conference, I was able to expand my network of contacts within the field, having the opportunity to meet and interact with scholars coming from diverse geographical backgrounds, including Africa and beyond. This experience has created possibilities for future collaborations in future research.”

African languages under-represented in NLP research and development
Both Bukula and Mabuya are part of a research team working on MasakhaneNER 2.0: Africa-centric Transfer Learning for Named Entity Recognition. According to the research abstract, African languages are spoken by over a billion people, but they are under-represented in NLP research and development. Multiple challenges exist, including the limited availability of annotated training and evaluation datasets as well as the lack of understanding of which settings, languages, and recently proposed methods like cross-lingual transfer will be effective. In their research paper, the research team explains their move towards solutions for these challenges, focusing on the task of named entity recognition (NER); and the creation of the largest to-date human-annotated NER dataset for 20 African languages.
For their poster presentation, Bukula and Mabuya discussed the research findings, highlighting the behaviour of state-of-the-art cross-lingual transfer methods in an Africa-centric setting, empirically demonstrating that the choice of source transfer language significantly affects performance. “While much previous work defaults to using English as the source language, the research team’s results show that choosing the best transfer language improves zero-shot F1 scores by an average of 14% over 20 languages as compared to using English.”
Both Bukula and Mabuya found it very rewarding to be able to explain the complexities of isiZulu and isiXhosa whenever they were approached with questions by those interested in the Nguni languages.
An absolute highlight for them was when they were invited to be part of the Practical AI podcast – Episode #205 to share about their work at SADiLaR and their individual interests. Listen to the podcast here: https://changelog.com/practicalai/205
(Written by Birgit Ottermann)


